GSoC: Michael Madsen
Game script (bytecode) decompilerPure grouping
I've just implemented pure grouping into the control flow analysis. So, what does that actually mean?The previous algorithm was tailored specifically to stack-based machines, exploiting the property that in an archetypical stack-based machine, you can detect individual lines of code based on when the stack is balanced. Although none of the generic code requires or makes use of this, it generates some very nice side effects: for example, conditions will be placed in a single group of their own.
Unfortunately, that doesn't work for non-stack-based machines: since the stack is not used, the stack is always balanced and no grouping can be performed with that algorithm. This is a big problem, because it generates a lot of vertices in the graph, and this causes dot to choke when trying to layout the graph.
Ideally, this would be handled by letting engines specify a custom grouping algorithm, since this would allow each engine to tailor the grouping to meet their needs (e.g. make sure conditions are in groups of their own). However, the code isn't really ready for that; the CFG was never re-designed due to a lack of concrete ideas, and any changes here could very easily affect the grouping algorithms as well, which may require substantial changes.
As a compromise, I've added something I call pure grouping, which only considers branches, much like the graph view found in IDA. This approach, which engines can opt-in to, creates the minimal amount of groups, and makes it much easier for dot to layout the graph, allowing visualization of the CFG, which makes it much more feasible to implement code generation for those engines, because you can more easily see what's going on.
For a concrete, visual example, here is a "pure" version of one of the SCUMM scripts I've previously shown here:
Had this been a non-stack-based engine, the old algorithm would have created 28 nodes in the graph - one per instruction. Pure grouping reduces that number to 7. For comparison, regular stack-based grouping generates 12 groups in this case.
Of course, that doesn't mean every engine should use pure grouping: if you have a stack-based engine which fits into the archetype, then it's usually a good idea to keep using the original algorithm because it works well for those engines, and I'm not changing KYRA or SCUMM to use pure grouping. However, other engines such as Groovie, which are not stack-based, should be able to benefit from this, if only by allowing visualization of their scripts.
Posted in Decompiler at 2011-02-08 23:20:02
Back to work
Finally, I have some time to work on the decompiler again!Actually, I've been working on it for a little while now, but I didn't want to make a big fuzz about it until I got a bit more done. :)
We never got the decompiler merged back into trunk, so one of my current tasks will be to get that done, and then people can have a go at adding new engines.
However, before doing that, I'm going to clean up the decompiler to make it "ready for primetime". The code is in need of a redesign, so that's what I'm busy doing right now. So far, I've changed almost every single file in order to prepare for objectifying the Instruction class, and the next step is to actually get that done.
I'll also see if I can do anything about the CFG to put some more info in there, and I'll try to get a couple of minor things done as well, such as merging Parameter and StackEntry to a single Value class hierarchy and getting rid of some unnecesasry parentheses in the output.
Once the redesign is done, the decompiler should finally be ready to get merged into trunk, and it'll be ready for more engines. I'm not sure exactly when this will happen, but right now, I'm kinda hoping to get this out before the end of the year - but if that fails, I should be able to get it done during January instead.
Posted in Decompiler at 2010-12-12 01:49:23
Goodbye... but I'll be back
At the time of writing, there are less than 2 hours left of GSoC coding time - so it's time for my last GSoC blog post.It's been a fun couple of months, and it's really nice to see that the end product actually works.
Of course, it's not perfect, and there are things I'd do differently if I were to do it again - but then, it would be pretty unrealistic to expect that everything could be perfect after only a few months. A decompiler is a complicated project, and making a generic kind doesn't make it any easier.
There are still plenty of stuff on the to-do list, and I've already talked to my mentors about how we can deal with several of the outstanding issues - but there's no way all of that can be done within the time frame allocated for GSoC.
Right now, though, I'm going to take a short break from coding - and later, I can hopefully find the time to work more on the decompiler and implement some of the remaining things.
Posted in GSoC at 2010-08-16 17:18:55
Kyra complete!
Well, I did manage to get the code generation running in just one day after all! That's means I have the entire weekend to rewrite the documentation, and there's still the final week after that for polishing everything off.Here's a function as seen in one of the scripts (INHOME.EMC):
00000F88: global_sub0xF88() {
00000F8A: if ((-1 < var4)) {
00000F94: if (!(var17)) {
00000F9C: var17 = 1;
00000FA0: retval = auto_sub0x33C(30, 0, 28);
00000FAC: retval = o1_queryGameFlag(2);
00000FB2: localvar1 = retval;
00000FB6: retval = o1_queryGameFlag(1);
00000FBC: localvar2 = retval;
00000FC0: var3 = 1;
00000FC4: if ((localvar2 && localvar1)) {
00000FCE: retval = o2_zanthiaChat("At least I found my cauldron and my spellbook.", 29);
00000FD6: return;
00000FDA: }
00000FDA: if (localvar1) {
00000FE0: retval = o2_zanthiaChat("At least I found my cauldron.", 30);
00000FE8: return;
00000FEC: }
00000FEC: if (localvar2) {
00000FF2: retval = o2_zanthiaChat("At least I found my spellbook.", 31);
00000FFA: return;
00000FFE: }
00000FFE: retval = auto_sub0x33C(34, 0, 32);
0000100A: retval = auto_sub0x33C(35, 0, 33);
00001016: return;
0000101C: } else {
0000101C: var17 = 0;
00001020: retval = o2_randomSceneChat();
00001020: }
00001022: var3 = 1;
00001026: return;
0000102A: }
0000102A: retval = o2_useItemOnMainChar();
0000102C: return;
0000102C: }
Currently, the decompiler only works with scripts from the talkie version of Kyra2, as one of the functions differ in the number of arguments - but I'll get that fixed before GSoC is over.Right now, though, I'll focus on the documentation - there's a lot of stuff that needs to be written and rewritten with the changes I've made for Kyra.
Kyra... CFG'd!
After some work, I've gotten a good, automatic function detection algorithm implemented in the CFG analysis, which engines can choose to opt-in to. This is perfect for Kyra, as some of these scripts really do require you to look at the control flow to determine where they stop.The algorithm is really pretty simple: we find any unreachable code that is not already inside a function, and follow the code flow to see where that piece of code ends - and that is then registered as a function. However, it still requierd quite a bit of rewriting to accomplish this properly, so it took a bit longer than I'd planned - but it should be worth it.
Here's a relatively small sample script from the HoF CD demo:

and just for the heck of it, here's a really big script (Warning: full image is 19873x16660 pixels large!):

Now, it's finally time for the code generation part of Kyra. I'd originally planned to finish it Friday, but this took a day longer than planned, so I have a feeling the code generation won't be ready before Saturday - but we'll see. At the very least, I should be able to get it done during the weekend, so I have all of next week to polish the documentation, clean up some of the code, add some small features that would be nice to have - stuff like that.
Kyra disassembled!
It's a day later than I'd estimated, but last night, I finished the Kyra disassembler, including function detection.For now, I'm only handling one game - Hand of Fate - but it would be pretty simple to add the other Kyra games as well, as the only things different between them are the "magic" functions, and they're all referred to by a parameter to a specific opcode. However, there's not much point in doing that right now; it won't help me to decompile the bytecode.
Here's an excerpt from the disassembly of a small script:
00000016: jumpTo 0x0 (0) 00000018: push 6 (1) 0000001a: push 3 (1) 0000001c: setCharacterPos (0) 0000001e: addSP 2 (-2) 00000020: push 6 (1) 00000022: push 2 (1) 00000024: setCharacterPos (0) 00000026: addSP 2 (-2)The next step is to get the code flow analysis working with KYRA, and then it's on to the code generation.
SCUMM over!
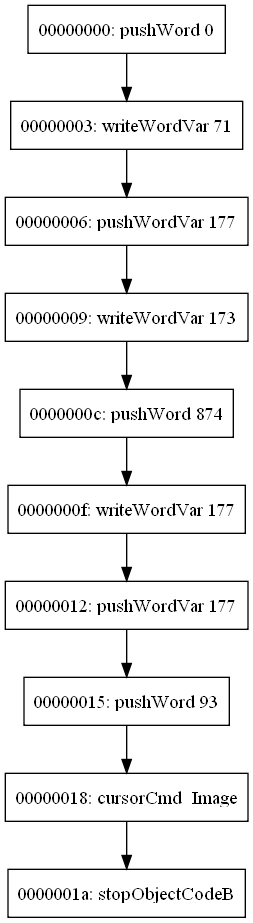
I've finished the SCUMM code generation now. Unfortunately, a bunch of stuff got in the way, and I didn't quite make my new revised deadline - but at least I finished in time for the original deadline.There may still be some tweaks here and there which would be nice to add, but the code generation is working for all opcodes, and generating some pretty nice output. To give an example, here is the complete output for the script I showed you last time:
C:\scummvm\gsoc2010-decompiler>decompile -escummv6 script-33.dmp 00000000: VAR_GAME_LOADED = 0; 00000006: var173 = var177; 0000000C: var177 = 874; 00000012: cursorCmd_Image(var177, 93); 0000001A: stopObjectCodeB();And just to show it does more than just such simple scripts, here's part of another, more complicated script:
C:\scummvm\gsoc2010-decompiler>decompile -escummv6 script-30.dmp
00000000: localvar2 = 1;
00000006: while ((localvar2 <= (60 * var132))) {
00000014: breakHere();
00000015: delaySeconds(1);
00000019: if (((VAR_VIRT_MOUSE_X != localvar0) || (VAR_VIRT_MOUSE_Y != localvar1))) {
0000002B: localvar0 = VAR_VIRT_MOUSE_X;
00000031: localvar1 = VAR_VIRT_MOUSE_Y;
00000037: jump 0;
0000003A: }
0000003A: if (bitvar1) {
00000040: bitvar1 = 0;
00000046: jump 0;
00000049: }
00000049: ++(localvar2);
0000004F: }
Now that all parts of the SCUMM decompilation have been handled, it's time to move on to the next engine - KYRA. My next task is therefore to get a disassembler for that written.First output!
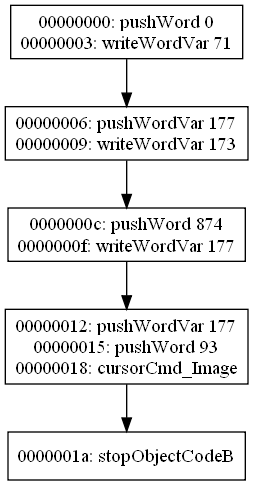
I finally have some actual output working. It's only a proof of concept right now, but it's a nice start.Here is the output the decompiler generates for one of the short Sam & Max scripts - one of the scripts I used for the code flow testing (link points to the graph for that script):
C:\scummvm\gsoc2010-decompiler>decompile -escummv6 script-33.dmp VAR_GAME_LOADED = 0; var173 = var177; var177 = 874; Unknown opcode 6B99 at address 00000018 Unknown opcode 66 at address 0000001AIt only does these simple assignments for now - everything else is left unknown - but like I said, it's a start.
The opcodes it complains about are cursorCmd_Image and stopObjectCodeB, since I don't handle those yet.
Re-assessment
After a brief discussion with my mentors, I'm going to use a different approach than I'd originally envisioned for the code generation part of the decompiler.Basically, I'm going to try and emulate the principle used by descumm for generating the SCUMM code. This approach should be simpler than what I had originally envisioned, but still sufficiently generic to work without too many changes for KYRA.
Since this approach is vastly different from the original plan, I'm also re-evaluating my milestone plan. The original plan puts the expected date for SCUMM code generation at July 24, but I think I'll be able to get this done a few days earlier than that - I'm guessing it'll be around July 21 instead, so I'm setting that as the new date for that milestone for now, although it is still a pretty rough estimate. In a day or two, I will hopefully have a much better feel about how long this will really take, and then I will look at changing the other milestones as well - and possibly re-evaluating this one as well.
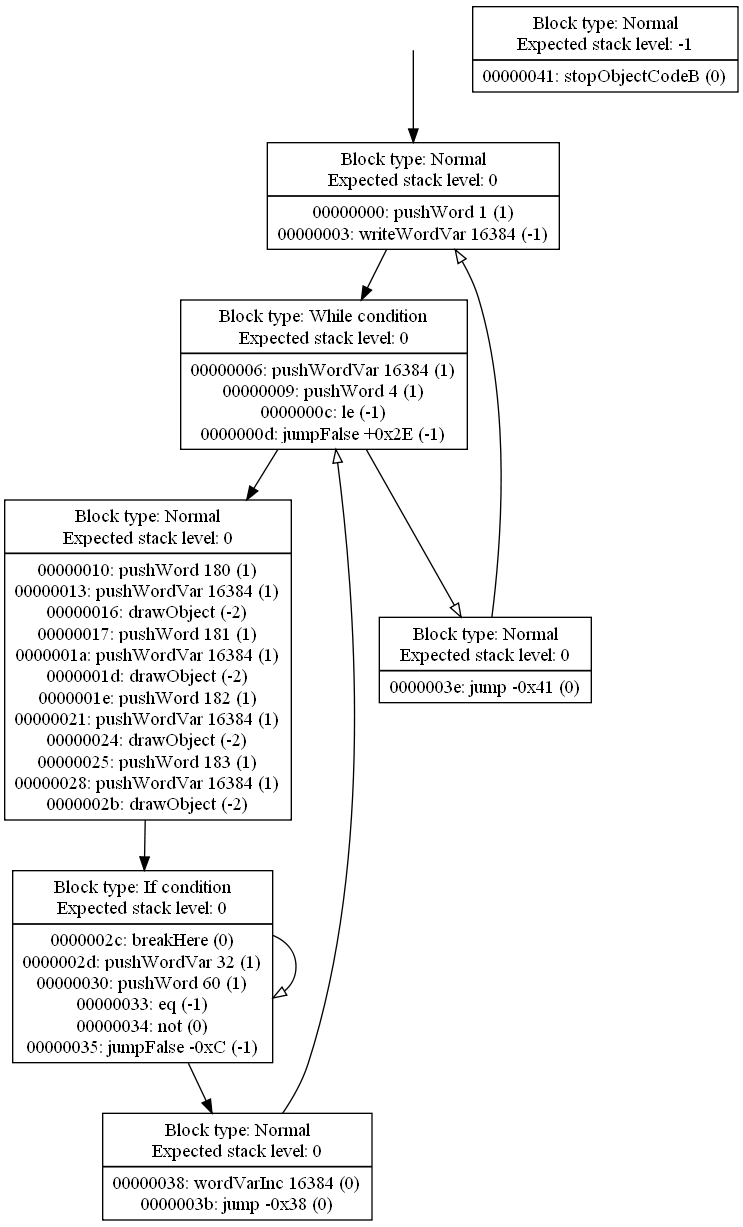
CFG analysis complete!
And with that, the CFG analysis is now completed and documented, completing the fourth milestone. There are still a couple of things that could be improved upon, but they are not applicable to SCUMM, so I'll leave those things alone for now and then I can get back to them if KYRA needs them (or if time permits later in the project).Here's an example of a script with all of the analysis complete:
It may seem a little messy, but I've verified it, and the analysis gives the expected results for everything.
The next milestone is code generation for SCUMMv6 - so each of these boxes must be converted to a piece of code. Once that milestone is complete, the decompiler should be able to fully decompile all SCUMMv6 scripts.
Posted in Decompiler, GSoC at 2010-07-05 16:43:28
Short-circuiting
I've just finished adding short-circuit detection to the decompiler. This detection is done as part of the initial group creation.The algorithm for detecting short-circuiting is as follows: Two groups, A and B, that follow sequentially in the byte code (no instructions appear between the last instruction of A and the first instruction of B), are merged if:
- Both group A and B end with a conditional jump (they have two possible successors each)
- For each outgoing edge from A, the edge must either go to B, or to a successor of B - in other words, merging may not add any new successors. More formally, succ(A) ⊆ {B} ∪ succ(B), where succ(X) is the possible successors for X.
Here's an example to show how this works. The number in parenthesis is the effect that instruction has on the stack, and for ease of reading, the jump addresses have been made absolute.
0x00: wordVarDec 123 (0) 0x03: pushWord 41 (1) 0x06: pushWordVar 321 (1) 0x09: eq (-1) 0x0a: jumpTrue 0x17 (-1) 0x0d: pushWord 42 (1) 0x10: pushWordVar 123 (1) 0x13: eq (-1) 0x14: jumpTrue 0x00 (-1) 0x17: stopObjectCodeA (0)Normally, there would be 4 groups in this script: the first and last instructions would be groups on their own, and instructions 0x03 through 0x0a would be a group, as would 0x0d through 0x14. For simplicitly, we'll number these groups 1 through 4.
0x00: wordVarDec 123 (0) === 0x03: pushWord 41 (1) 0x06: pushWordVar 321 (1) 0x09: eq (-1) 0x0a: jumpTrue 0x17 (-1) === 0x0d: pushWord 42 (1) 0x10: pushWordVar 123 (1) 0x13: eq (-1) 0x14: jumpTrue 0x00 (-1) === 0x17: stopObjectCodeA (0)The possible successors for group 3 are group 4 and group 1, while the possible suceessors for group 2 are group 3 and group 4. Since group 4 is a shared successor, and the group 2-group 3 link becomes irrelevant due to the merge, the two groups can be merged to a single one since the algorithm detects them as a short-circuited condition check.
Posted in Decompiler, GSoC at 2010-07-01 23:08:14
I'm back!
New computer is assembled and seems to be running perfectly. It even seems a bit quieter than the previous one, but I haven't had the GPU actually do real work yet, so maybe that'll change things. :)Hopefully, I can make up for the lost time once I'm done with my last exam on Wednesday.
Posted in GSoC at 2010-06-26 12:09:23
Unexpected downtime...
As luck would have it, the CPU fan on my desktop machine has stopped working properly. That's not good, because that's the machine I do most of my development on.I still have my laptop, and I should be able to get some work done here. Unfortunately, it's not as comfortable to work with as my desktop, and that means there's a good chance it'll harm my productivity and have an impact on the schedule.
I was planning to replace most of the parts anyway, so I'm currently considering if I should do that now, or if I should wait and just buy a new fan now. It's not that a new fan is expensive, but if I'll be replacing the CPU in a month or two anyway, then it might make more sense to just get it done now.
I'll figure out what to do over these next few days - if I replace everything, then it'll probably be about 2 weeks before I get it back up and running, or if I just replace the fan, it should be ready some time during the upcoming week.
Right now, I'm going to focus on my next exam on Tuesday, and at the same time, I'll try to figure out what I'm going to do about this as well. After that, I can get back to work on the code flow analysis.
Posted in GSoC at 2010-06-20 19:08:48
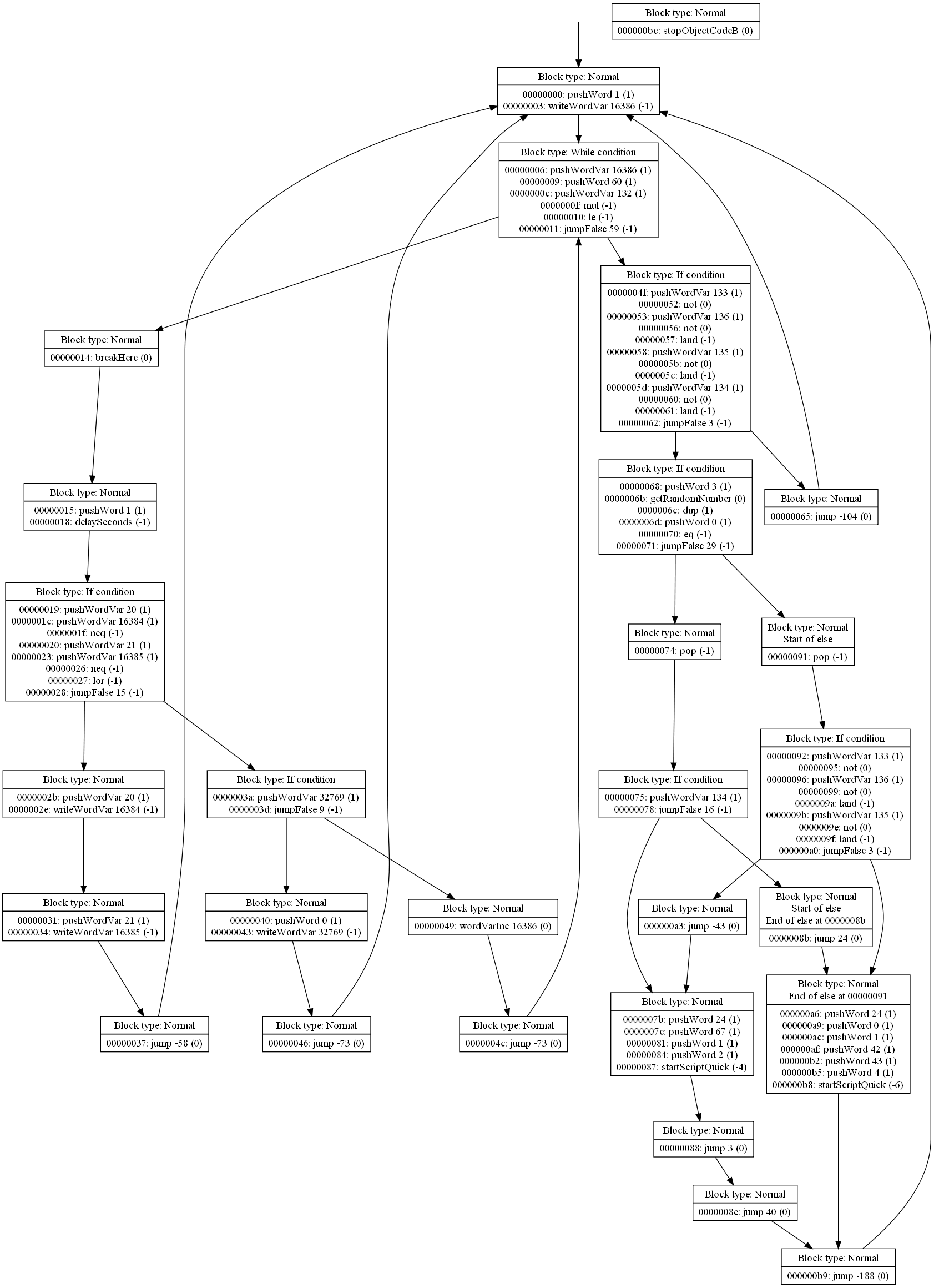
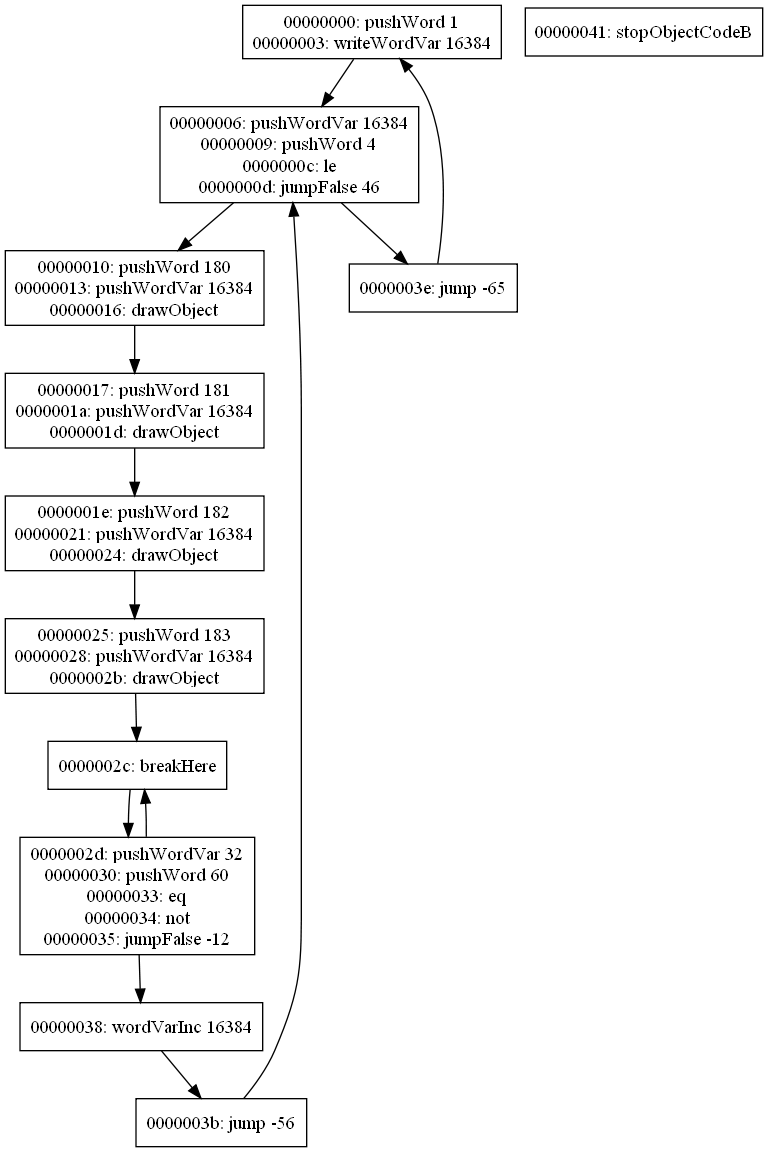
Grouping completed!
Well, that didn't take long.Vertices in the code flow graph are now grouped according to these rules:
- Only consecutive instructions may be grouped.
- If there is a jump, it must be the last instruction in the group.
- If there is a jump to an instruction, that instruction must be the first instruction in the group.
- Once the stack becomes balanced, the group ends with the instruction that balanced the stack.
Here are the scripts from the last post, but now with grouping:
And finally, as an example of a really big graph:

This concludes the third milestone. The next step is to analyze the graph to detect loops and conditionals.
Posted in Decompiler, GSoC at 2010-06-14 21:55:01
Initial code flow
Finally, I've been able to start work on the code flow graph.So far, very little is prepared, but I can now make the most basic graph, with each instruction as its own vertex (click for full-size image):
Additionally, jumps are also handled (click for full-size image):

The next step is to combine some of these instructions into groups of instructions, to reduce the number of vertices in the graph.
Posted in Decompiler, GSoC at 2010-06-13 15:08:33
First disassembler done!
The SCUMM disassembler is now complete, completing the second milestone.As mentioned in my previous post, the next step is to write documentation on this, and then it's on to the code flow graph.
One week in...
That concludes the first week of the project.I finished the first milestone a few days ahead of schedule, and got started on the next one, the SCUMMv6 disassembler. Since the opcode documentation on the ScummVM wiki isn't really complete, that requires me to jump back and forth between files and make sure I properly understand the code, so it doesn't go as quickly as it probably could - however, I should still have plenty of time to finish the disassembler by the milestone deadline, June 8.
Once the disassembler's done, I'll write some documentation on creating a disassembler, while I'm still focused on that part of the decompiler.
Posted in Decompiler, GSoC at 2010-06-01 23:55:13
And so it begins...
May 24th just passed - and so, it is now that coding begins.In order to help me keep track of all the things I need to do, I have setup a local installation of Trac, where I add the individual subtasks and assign them to milestones.
This is a very useful tool on its own, but it would certainly be more useful if I could show my progress directly to the world as things progress. Because of this, I wrote a small tool which is set up to periodically extract my task list and upload it online. This way, everyone can keep up with exactly what's happening.
The list is updated every 15 minutes, as long as my primary computer is switched on. You can see in the title bar when the list was last generated.
The task list is available at http://blog.birdiesoft.dk/tracreport/. I have also added a link in the sidebar.
Posted in Decompiler, GSoC at 2010-05-25 01:10:39
Project outline
I figure it's about time that I post a bit more about what I'll be doing.As I mentioned in my first post, my task is to create a generic script decompiler. That's a bit vague, though - it can't magically know how to decompile everything, and there's no way I have time enough to teach it everything.
Instead, I'll make it work with two different engines: SCUMMv6 and KYRA. For SCUMMv6, I own Sam & Max, and for KYRA, I have a demo of Hand of Fate, so both of these will come in handy when testing the decompiler.
Why those two engines? Well, apart from being pretty well understood, my mentors are also familiar with these engines. Although I could choose engines that neither of them know anything about, that would be a pretty foolish idea, since it'd be harder for me to get help if (well, most likely when) I need it.
The reason for taking two engines is simple: if I only did one engine, it'd be hard to show that I actually took a generic approach. It's the same problem if I just did two different version of an engine - it might need to be a bit more generic in order to allow for both versions, but it doesn't say anything about whether the approach will easily extend to other engines.
So now that we know what the end goal is, let's talk about how we're going to get there. I've prepared a schedule, and here are the primary points on it:
- June 1: Disassembly framework
- June 8: First disassembler (SCUMMv6)
- June 21: Generation of code flow graph
- June 28: Code flow analysis
- July 24: Code generation (SCUMMv6)
- July 29: Second disassembler (KYRA)
- August 6: Code generation (KYRA)
So there you have it - a brief overview of my project. In later posts, I'm going to cover these steps in more detail.
Posted in Decompiler, GSoC at 2010-05-06 23:05:56
Hello, world!
Hi! I'm Michael Madsen, I'm studying computer science at Aalborg University in Denmark, and I've been accepted as a GSoC student to work on ScummVM.My task is to create a generic script decompiler, such that it allows adding support for new instruction sets without too much work.
Readers familiar with ScummVM GSoC projects might think this project sounds familiar - and that's probably because it's already been attempted twice, in 2007 and 2009.
So why would my attempt fare better than the previous ones, apart from the old proverb "Third time's the charm"? Well, there is of course no guarantee that it will - but I believe I have a skill set which is suitable for this task. I enjoy working with low-level stuff, I have good logic skills, and I have some experience with writing compilers from the semester project we did at university a year ago, which should be useful when writing a decompiler.
Over this next month, I will be preparing for the coding process by studying documentation and the instruction sets I'll be working with, looking for things that stand out as a potential source of problems and otherwise getting familiar with the engines, maybe prepare a few tools which I expect will help me.
I've already prepared (very) rough sketches of the algorithms I need to use, and I will spend some time refining them a bit more to get them ready to implement.
I don't really have much more to say, so if you have questions, you can e-mail me, leave a comment, or catch me on IRC (where I go by the name of Pidgeot). I look forward to working on the project, and I hope you will like the outcome.
Posted in GSoC at 2010-04-26 22:40:12