GSoC: Michael Madsen
Game script (bytecode) decompilerPure grouping
I've just implemented pure grouping into the control flow analysis. So, what does that actually mean?The previous algorithm was tailored specifically to stack-based machines, exploiting the property that in an archetypical stack-based machine, you can detect individual lines of code based on when the stack is balanced. Although none of the generic code requires or makes use of this, it generates some very nice side effects: for example, conditions will be placed in a single group of their own.
Unfortunately, that doesn't work for non-stack-based machines: since the stack is not used, the stack is always balanced and no grouping can be performed with that algorithm. This is a big problem, because it generates a lot of vertices in the graph, and this causes dot to choke when trying to layout the graph.
Ideally, this would be handled by letting engines specify a custom grouping algorithm, since this would allow each engine to tailor the grouping to meet their needs (e.g. make sure conditions are in groups of their own). However, the code isn't really ready for that; the CFG was never re-designed due to a lack of concrete ideas, and any changes here could very easily affect the grouping algorithms as well, which may require substantial changes.
As a compromise, I've added something I call pure grouping, which only considers branches, much like the graph view found in IDA. This approach, which engines can opt-in to, creates the minimal amount of groups, and makes it much easier for dot to layout the graph, allowing visualization of the CFG, which makes it much more feasible to implement code generation for those engines, because you can more easily see what's going on.
For a concrete, visual example, here is a "pure" version of one of the SCUMM scripts I've previously shown here:
{kind=link}
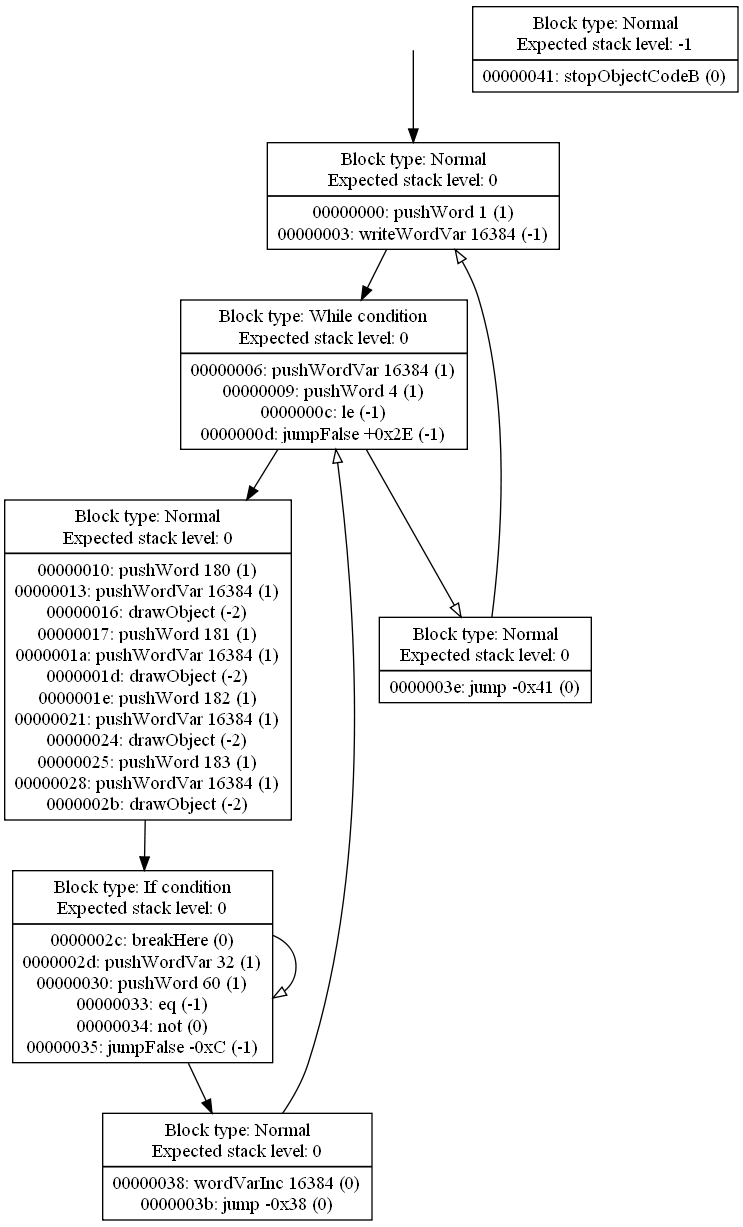
Had this been a non-stack-based engine, the old algorithm would have created 28 nodes in the graph - one per instruction. Pure grouping reduces that number to 7. For comparison, regular stack-based grouping generates 12 groups in this case.
Of course, that doesn't mean every engine should use pure grouping: if you have a stack-based engine which fits into the archetype, then it's usually a good idea to keep using the original algorithm because it works well for those engines, and I'm not changing KYRA or SCUMM to use pure grouping. However, other engines such as Groovie, which are not stack-based, should be able to benefit from this, if only by allowing visualization of their scripts.
Posted in Decompiler at 2011-02-08 23:20:02